
Zusammenfassung
Verfasst von Marcus A. Volz. Maschinelles Lernen bildet das Fundament moderner KI-Systeme, aber nicht alle Modelle lernen gleich. Während Supervised Learning auf klar gelabelte Daten setzt und präzise Klassifikationen ermöglicht, entdeckt Unsupervised Learning eigenständig verborgene Muster und semantische Strukturen. Beide Ansätze prägen, wie künstliche Intelligenz Bedeutung konstruiert – von der Spam-Erkennung bis zu kontextuellen Embeddings in der Suche.
Supervised vs. Unsupervised Learning – Wie Maschinen Bedeutung lernen
1. Lernen aus Daten – nicht aus Erfahrung
Maschinen „lernen" nicht wie Menschen. Sie erfassen keine Konzepte, sondern berechnen Wahrscheinlichkeiten. Trotzdem führt die wiederholte Beobachtung von Mustern dazu, dass Modelle Bedeutungsräume aufbauen – also Beziehungen zwischen Wörtern, Sätzen oder Bildern, die für uns semantisch wirken.
Wenn ein Algorithmus erkennt, dass „König" und „Königin" ähnlich sind oder dass „Mann" und „Frau" in einer verwandten Beziehung stehen, ist das kein menschliches Verständnis, sondern eine mathematische Annäherung an Bedeutung. Der entscheidende Punkt ist, wie diese Strukturen entstehen: durch Anweisung oder durch Entdeckung.
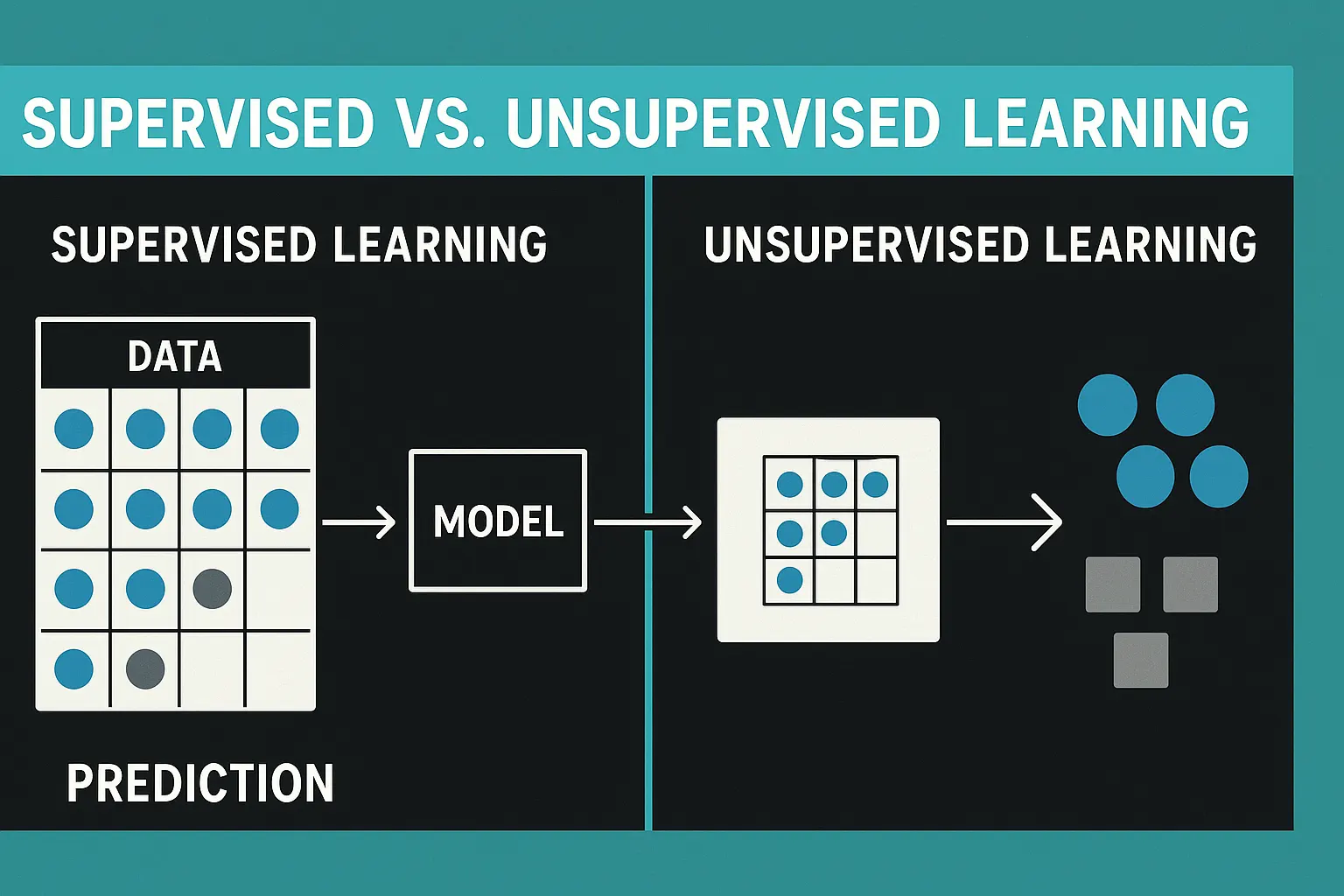
2. Supervised Learning – Lernen mit Anleitung
Supervised Learning funktioniert nach dem Prinzip der Anleitung. Das Modell erhält Eingabedaten und die dazugehörigen Ausgabewerte. Es weiß also, welche Antwort richtig ist. Dadurch kann es lernen, die Beziehung zwischen Eingabe und Ausgabe herzustellen. Dieses Verfahren wird häufig für Klassifikationen oder Prognosen verwendet.
Beispiel: Spam-Erkennung
Die Trainingsdaten bestehen aus E-Mails, die jeweils als „Spam" oder „nicht Spam" markiert sind. Das Modell lernt, welche Muster zu einem dieser Labels führen, und kann später neue E-Mails korrekt einordnen.
3. Der Prozess des überwachten Lernens
Das Training im Supervised Learning verläuft iterativ. Das Modell trifft zunächst eine Vorhersage, vergleicht sie mit dem tatsächlichen Label und korrigiert den Fehler. Dieser Zyklus wiederholt sich tausendfach, bis die Abweichung minimal ist. Das Ergebnis ist ein System, das gelernt hat, bekannte Muster zu reproduzieren.
Die Stärke dieses Ansatzes liegt in der Kontrolle. Da die Daten gelabelt sind, lässt sich die Genauigkeit überprüfen und gezielt optimieren. Für viele Anwendungen – von der medizinischen Diagnose über Kreditbewertungen bis hin zur Sprachklassifikation – ist Supervised Learning daher unverzichtbar.
Doch der Preis für diese Präzision ist hoch: Supervised Learning benötigt große Mengen gelabelter Daten, und diese sind aufwendig, teuer und häufig subjektiv. Wenn Labels unvollständig oder falsch sind, übernimmt das Modell diese Fehler. Es lernt nur, was ihm gezeigt wird – nicht mehr.
4. Die Grenzen des Überwachten
In linguistischer Analogie entspricht Supervised Learning einem Schüler, der alle Vokabeln eines Lehrbuchs auswendig kann, aber außerhalb dieses Rahmens kaum kommunizieren kann. Das System generalisiert nur in begrenztem Maß. Für dynamische Bedeutungen, neue Wortverwendungen oder sprachliche Nuancen ist es daher oft zu starr.
Supervised Learning bietet also Zuverlässigkeit und Präzision, aber keine kreative Entdeckung. Es bleibt ein „Lernen nach Vorschrift".
5. Unsupervised Learning – Lernen durch Entdeckung
Unsupervised Learning folgt einem anderen Prinzip. Hier gibt es keine vorgegebenen Antworten, keine Zielvariablen und keine Labels. Das Modell erhält unstrukturierte Daten und soll selbst Muster erkennen. Es weiß nicht, was richtig oder falsch ist, sondern sucht Ähnlichkeiten, Distanzen und Gruppierungen.
Damit kann es Strukturen entdecken, die vorher gar nicht bekannt waren. Die bekanntesten Methoden sind:
- Clustering (z. B. K-Means) – Datenpunkte mit ähnlichen Eigenschaften werden zu Gruppen zusammengefasst, etwa Kunden mit ähnlichem Kaufverhalten oder Texte mit ähnlichem Stil
- Dimensionsreduktion (z. B. PCA) – komplexe Daten werden vereinfacht, um versteckte Zusammenhänge sichtbar zu machen
Beispiel: Automatische Themengruppierung
Ein Nachrichtenportal nutzt Clustering, um tausende Artikel automatisch nach Themen zu gruppieren – ohne dass jemand vorher definiert hat, welche Kategorien existieren. Das Modell erkennt eigenständig Muster wie „Wirtschaft", „Sport" oder „Technologie".
6. Bedeutung entsteht aus Kontext
Gerade für semantische Modelle ist Unsupervised Learning zentral. Sprachmodelle wie Word2Vec oder GloVe basieren darauf, dass Wörter, die häufig im selben Kontext vorkommen, auch inhaltlich ähnlich sind. Das Modell braucht keine Annotation, um zu erkennen, dass „Auto" und „Fahrzeug" verwandt sind. Es lernt Bedeutung aus Ko-Vorkommen.
Diese Methode bildet den Grundstein für moderne Embeddings, in denen jedes Wort als Vektor in einem mehrdimensionalen Raum dargestellt wird. Die Nähe dieser Vektoren spiegelt semantische Ähnlichkeit wider. Bedeutung entsteht hier nicht durch menschliche Erklärung, sondern durch das statistische Muster selbst – ein emergentes Phänomen.
7. Strukturen ohne Anleitung – Chancen und Grenzen
Der Nachteil des Unsupervised Learning liegt in der Interpretierbarkeit. Es liefert keine klaren Labels, sondern Strukturen, die erst nachträglich gedeutet werden müssen. Die Ergebnisse hängen stark von Parametern und der Datenqualität ab. Dennoch besitzt diese Lernform eine entscheidende Stärke: Sie ist offen und kreativ.
Das Modell kann Zusammenhänge erkennen, die Menschen übersehen. Es entdeckt Kategorien, Beziehungen oder Themen, die in den Daten implizit enthalten sind. In der linguistischen Analogie ist Unsupervised Learning ein Forscher, der eine neue Sprache allein durch Beobachtung lernt – ohne Wörterbuch, nur durch Mustererkennung.
8. Zwischenformen: Semi- und Self-Supervised Learning
Zwischen beiden Polen liegen Mischformen. Semi-supervised Learning nutzt teilweise gelabelte Daten und kombiniert sie mit unbeschrifteten. Das ist besonders nützlich, wenn nur wenige Trainingsdaten vorhanden sind.
Eine Sonderform ist das Self-supervised Learning, das in modernen Sprachmodellen wie BERT, GPT oder Gemini eine zentrale Rolle spielt. Hier erzeugt das Modell seine Trainingsaufgaben selbst – zum Beispiel, indem es Wörter aus einem Satz entfernt und versucht, sie anhand des Kontexts wiederherzustellen. Dadurch verbindet es die Struktur des Supervised Learning mit der Offenheit des Unsupervised Learning. So entsteht kontextuelles Verständnis, ohne dass menschliche Labels nötig sind.
9. Zwei Wege zur Bedeutung
Die Gegenüberstellung zeigt zwei Wege zum gleichen Ziel: das Erkennen von Bedeutung in Daten.
Supervised Learning funktioniert wie Unterricht – klar, zielgerichtet, aber begrenzt auf das Bekannte.
Unsupervised Learning gleicht Forschung – explorativ, unscharf, aber kreativ.
Beide sind notwendig. Ohne Supervised Learning gäbe es keine klaren Klassifikationen oder Bewertungen. Ohne Unsupervised Learning gäbe es keine Entdeckung neuer Strukturen und keine emergenten Bedeutungsräume.
10. Verbindung in der semantischen Suche
In der semantischen Suche finden beide Prinzipien zusammen. Wenn ein Nutzer eine Frage stellt, vergleicht das System die Anfrage mit Millionen von Vektoren. Diese Vektoren stammen aus unsupervised gelernten Embeddings. Die Relevanzbewertung, die entscheidet, welche Ergebnisse angezeigt werden, basiert jedoch häufig auf supervised trainierten Modellen.
Die KI versteht die Bedeutung der Anfrage nicht, weil sie ein Wörterbuch besitzt, sondern weil sie Strukturen gelernt und durch menschlich validierte Daten verfeinert hat. Die Kombination beider Lernformen schafft etwas, das an maschinelles Verständnis erinnert.
11. Bedeutungserkennung im Zeitalter der KI
Für die semantische Bedeutungserkennung ist die Verbindung beider Lernarten entscheidend. Supervised Learning sorgt für Stabilität und Nachvollziehbarkeit, Unsupervised Learning für Kontext und Tiefe. Erst durch ihr Zusammenspiel entsteht die Fähigkeit, die moderne KI auszeichnet: Bedeutung jenseits einzelner Wörter zu erfassen.
Deep Learning, Embeddings und Modelle wie BERT oder Gemini bauen genau darauf auf. Sie verbinden die expliziten Strukturen des Supervised Learning mit den emergenten Mustern des Unsupervised Learning – und erzeugen so eine Art hybrides Lernen der Bedeutung.
12. Fazit – Zwei Seiten derselben Erkenntnis
Die Grenze zwischen Supervised und Unsupervised Learning wird zunehmend fließend. Je komplexer Modelle werden, desto mehr entsteht Wissen durch Selbstbeobachtung: Das System nutzt eigene Fehler, um sich zu verbessern. Bedeutung wird nicht mehr vorgegeben, sondern entwickelt sich aus Millionen von Verbindungen.
Supervised Learning steht für das Wissen, das uns erklärt wird.
Unsupervised Learning steht für das Wissen, das wir entdecken.
Beide Wege führen zur Konstruktion von Bedeutung – im Menschen wie in der Maschine.
Über den Autor
Marcus A. Volz ist Wirtschaftswissenschaftler, Linguist und Berater für semantische SEO. Er analysiert, wie Suchmaschinen Bedeutung verstehen und wie Marken durch semantische Klarheit sichtbar werden. Als Gründer von eLengua verbindet er ökonomisches Denken mit linguistischer Präzision, um Unternehmen im Zeitalter der KI-Suche strategisch zu positionieren. Sein Fokus liegt auf Entity SEO, semantischer Architektur und der Optimierung von Markenidentitäten in generativen Systemen.
Häufig gestellte Fragen (FAQ)
Was ist der Unterschied zwischen Supervised und Unsupervised Learning?
Supervised Learning arbeitet mit gelabelten Daten und lernt durch Anleitung. Unsupervised Learning erhält keine Vorgaben und entdeckt selbstständig Muster und Strukturen in den Daten.
Wofür wird Supervised Learning eingesetzt?
Supervised Learning wird für Klassifikationen und Prognosen verwendet – etwa Spam-Erkennung, medizinische Diagnosen, Kreditbewertungen oder Sprachklassifikation. Überall dort, wo klare Kategorien und präzise Vorhersagen nötig sind.
Was sind typische Anwendungen von Unsupervised Learning?
Clustering (Kundensegmentierung, Themengruppierung), Dimensionsreduktion, Anomalieerkennung und vor allem semantische Embeddings wie Word2Vec oder GloVe, die Bedeutung aus Ko-Vorkommen lernen.
Warum ist Unsupervised Learning wichtig für semantische Suche?
Weil es Bedeutung aus Kontext lernt, ohne dass jemand vorher Labels vergeben muss. Sprachmodelle erkennen so automatisch, dass „Auto" und „Fahrzeug" semantisch verwandt sind – durch statistische Muster in großen Textmengen.
Was sind die Nachteile von Supervised Learning?
Es benötigt große Mengen gelabelter Daten, die aufwendig und teuer sind. Falsche oder verzerrte Labels führen zu fehlerhaften Modellen. Zudem generalisiert Supervised Learning nur begrenzt und ist oft zu starr für neue, unbekannte Situationen.
Was sind die Herausforderungen bei Unsupervised Learning?
Die Ergebnisse sind schwerer zu interpretieren, da keine klaren Labels existieren. Die Qualität hängt stark von Parametern und Datenqualität ab. Strukturen müssen nachträglich gedeutet werden, was Expertise erfordert.
Was ist Self-Supervised Learning?
Self-Supervised Learning ist eine Hybridform, bei der das Modell seine eigenen Trainingsaufgaben erstellt – etwa indem es Wörter maskiert und versucht, sie aus dem Kontext vorherzusagen. BERT, GPT und Gemini nutzen diese Methode.
Wie entstehen Embeddings durch Unsupervised Learning?
Embeddings entstehen, indem Wörter als Vektoren in einem mehrdimensionalen Raum dargestellt werden. Wörter, die häufig in ähnlichen Kontexten vorkommen, erhalten ähnliche Vektoren – so entsteht semantische Nähe ohne menschliche Annotation.
Welche Lernform ist besser?
Keine ist grundsätzlich besser – beide haben unterschiedliche Stärken. Supervised Learning bietet Präzision und Kontrolle, Unsupervised Learning ermöglicht Entdeckung und Flexibilität. Moderne KI-Systeme kombinieren beide Ansätze.
Wie lernen Maschinen eigentlich Bedeutung?
Maschinen berechnen statistische Muster und Wahrscheinlichkeiten – sie „verstehen" nicht im menschlichen Sinne. Durch wiederholte Beobachtung von Ko-Vorkommen und Kontexten entstehen jedoch Strukturen, die semantische Beziehungen mathematisch abbilden.