
Zusammenfassung
Verfasst von Marcus A. Volz. Entitäten bilden das Fundament des semantischen Webs, doch ihre wahre Bedeutung entsteht erst durch Beziehungen. Dieser Artikel zeigt, wie Google Relationen zwischen Entitäten erkennt, bewertet und speichert – von der Tripel-Logik über linguistische Indikatoren bis zur Validierung im Knowledge Graph. Die Mechanik hinter der Verknüpfung ist das Herzstück semantischer Suche und entscheidend für moderne SEO-Strategien.
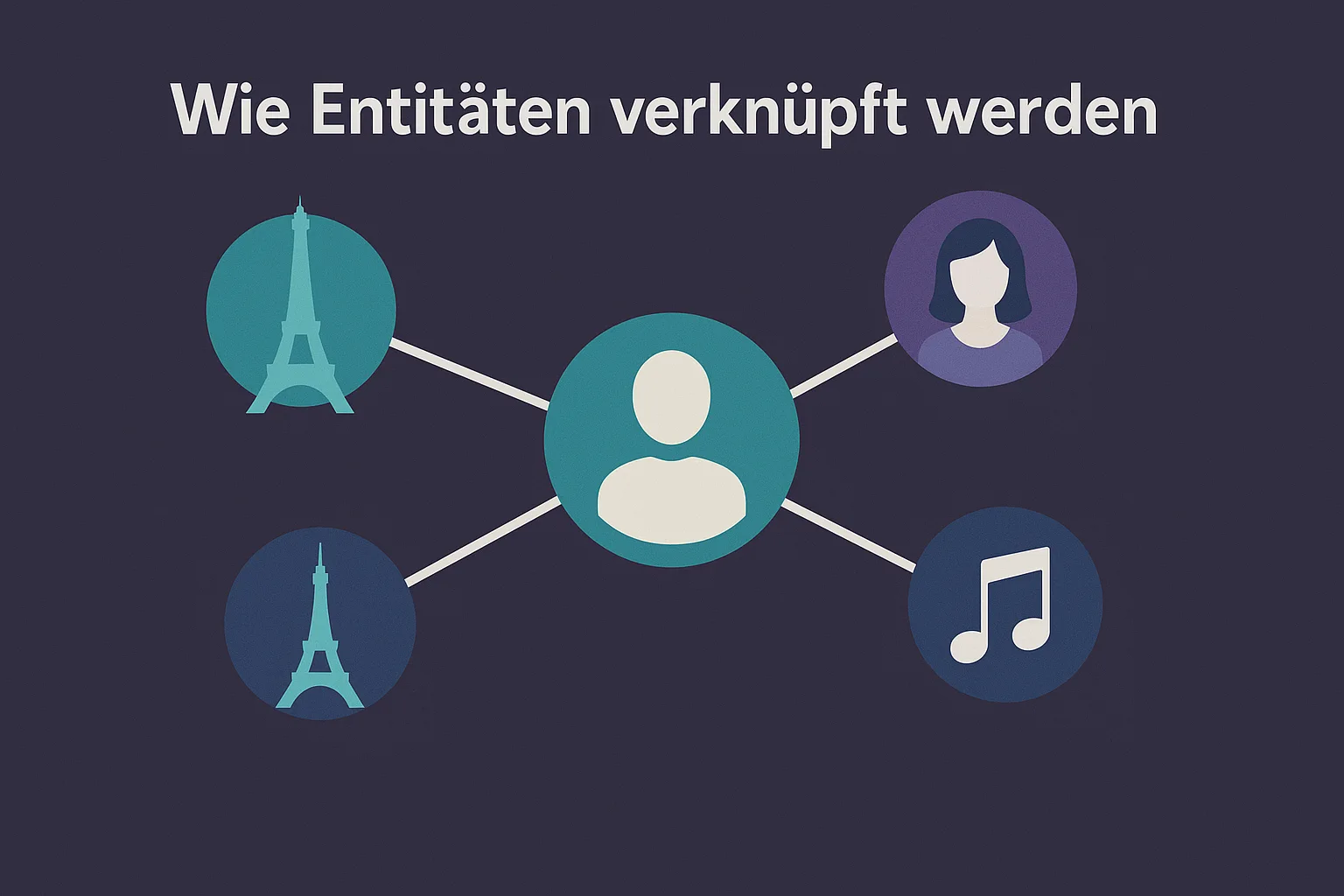
Wie Entitäten verknüpft werden – Vom Begriff zur Beziehung im Knowledge Graph
Einleitung – Vom Begriff zur Beziehung
Entitäten bilden das Fundament des semantischen Webs, doch ihre wahre Bedeutung entsteht erst durch die Beziehungen, die sie miteinander verbinden.
Ein einzelner Name, Ort oder Begriff bleibt ohne Kontext ein isoliertes Datenfragment. Erst wenn Verbindungen hergestellt werden – zwischen Personen, Ereignissen, Werken und Ideen – entsteht Wissen.
Wenn Suchmaschinen verstehen, dass Galileo Galilei eine Person ist, die das Teleskop erfand und in Pisa geboren wurde, verwandeln sie Sprache in Struktur.
Diese Fähigkeit, Beziehungen zwischen Entitäten zu erkennen, zu bewerten und zu speichern, ist das Herzstück des Google Knowledge Graph.
Der folgende Artikel zeigt, wie diese Verknüpfungen entstehen, wie sie gewichtet werden und warum sie für semantische SEO entscheidend sind.
1. Grundprinzip: Relation statt Erwähnung
Das bloße Erkennen einer Entität ist nicht genug.
Suchsysteme müssen verstehen, in welchem Verhältnis eine Entität zu anderen steht.
Zwischen Erkennung und Verknüpfung liegt der entscheidende Schritt: die Bildung einer Relation.
Die Tripel-Struktur
Diese Relationen werden in sogenannten Tripeln dargestellt – einer der wichtigsten Struktureinheiten des semantischen Webs:
Subjekt – Prädikat – ObjektBeispiel:
Isaac Newton – schrieb – Principia MathematicaDas Tripel beschreibt eine minimale Wissenseinheit. Millionen solcher Tripel bilden den semantischen Raum, aus dem Google die Zusammenhänge zwischen Dingen, Personen und Konzepten berechnet.
Dadurch wird aus einem Text nicht nur Information, sondern maschinenlesbare Bedeutung.
2. Linguistische und semantische Indikatoren
Damit Suchsysteme Relationen erkennen können, analysieren sie die sprachliche Struktur eines Satzes.
Verben, Präpositionen und Satzbau liefern Hinweise auf die Art der Beziehung.
Syntaktische Varianten
Beispiele:
„Marie Curie entdeckte das Radium."
„Das Radium wurde von Marie Curie entdeckt."
Beide Sätze beschreiben dieselbe Relation, nur mit unterschiedlicher Syntax.
Maschinelle Modelle zur Relationsextraktion erkennen diese Muster unabhängig von Wortstellung oder Passivform.
Syntaktische Abhängigkeiten
Dabei werden folgende Fragen beantwortet:
- Wer ist Handelnder, wer ist Objekt?
- Welches Verb drückt die Verbindung aus?
- Passt die Relation zum semantischen Kontext?
Diese linguistische Ebene wird mit semantischen Daten abgeglichen – etwa ob „entdeckte" zu wissenschaftlichem Kontext passt oder ob „Curie" in Wissensquellen als Forscherin beschrieben ist.
3. Statistische Signale und semantische Nähe
Neben Grammatik nutzt Google auch statistische Signale.
Wenn zwei Begriffe überdurchschnittlich häufig in ähnlichen Kontexten erscheinen, entsteht eine semantische Nähe.
Beispiel:
„Berlin" und „Deutschland" treten in Millionen von Dokumenten gemeinsam auf – häufiger als „Berlin" und „Italien".
Diese Häufung stärkt die Beziehung: Berlin → Hauptstadt von → Deutschland
Vektorräume und Bedeutungskorrelation
Solche Zusammenhänge werden in Vektorräumen modelliert:
Jede Entität erhält eine Position im semantischen Raum, und der Abstand zwischen ihnen spiegelt ihre Bedeutungskorrelation wider.
Das System lernt auf diese Weise, dass „Mozart" näher bei „Komponist" liegt als bei „Astronom".
So werden sprachliche Muster durch statistische Stabilität abgesichert.
4. Formale Darstellung im Knowledge Graph
Im Knowledge Graph werden Relationen nicht in Sprache, sondern in Datenstrukturen gespeichert.
Jede Entität ist ein Knoten (Node), jede Beziehung eine Kante (Edge).
Wikidata-Struktur
Die Verbindung folgt der Tripel-Logik, erweitert um Metadaten:
Beispiel:
Q64 (Berlin) → capital of (P36) → Q183 (Deutschland)Hierbei bedeutet:
- Q64 = eindeutige Kennung (Machine ID) für Berlin
- P36 = Property-ID für die Relation „Hauptstadt von"
- Q183 = Kennung für Deutschland
Zusätzlich können Qualifikatoren (z. B. Zeitraum) und Belege (z. B. Quelle) ergänzt werden.
So entsteht ein relationales System, das nicht nur weiß, was stimmt, sondern auch wann und woher.
5. Der Prozess der Verknüpfung
Damit Relationen korrekt entstehen, durchläuft Google mehrere aufeinanderfolgende Schritte:
1. Erkennung
Entitäten werden in Texten oder strukturierten Daten identifiziert.
2. Kandidatenbildung
Für jede Erwähnung werden mögliche Übereinstimmungen im Knowledge Graph gesucht.
3. Relationsextraktion
Verben, Satzstruktur und Kontextsignale werden ausgewertet, um potenzielle Beziehungen zu finden.
4. Disambiguierung
Mehrdeutige Zuordnungen (z. B. „Paris" – Stadt oder Person?) werden aufgelöst.
5. Validierung
Die neu entdeckte Relation wird mit bestehenden Daten verglichen. Stimmen mehrere Quellen überein, gilt sie als bestätigt.
6. Integration
Bestätigte Relationen werden mit Vertrauenswert im Knowledge Graph gespeichert.
Dieses Verfahren kombiniert linguistische, statistische und semantische Logik. Es ermöglicht, dass aus einzelnen Sätzen ein konsistentes Wissensnetz entsteht.
6. Arten von Relationen
Nicht alle Beziehungen sind gleich. Der Knowledge Graph unterscheidet verschiedene Typen:
Hierarchische Relationen
Beschreiben Zugehörigkeit oder Klassifikation:
Himalaya – ist Teil von – AsienFunktionale Relationen
Beschreiben Rollen oder Tätigkeiten:
Marie Curie – arbeitete für – SorbonneTemporale Relationen
Beziehen sich auf Zeiträume oder Ereignisse:
Nelson Mandela – war Präsident von – Südafrika (1994–1999)Kausale Relationen
Stellen Ursache und Wirkung her:
Vulkanausbruch – verursachte – TsunamiJede dieser Relationen folgt eigenen logischen Regeln. Kausale Verbindungen erfordern meist mehrere Belege, temporale Relationen benötigen Zeitangaben, hierarchische Relationen verweisen auf Taxonomien oder Ontologien.
7. Validierung und Gewichtung
Damit das System entscheidet, welche Relationen verlässlich sind, bewertet es sie nach Wahrscheinlichkeit.
Confidence Score
Dieser Vertrauenswert ergibt sich aus:
- Anzahl und Qualität der Quellen
- Übereinstimmung zwischen sprachlicher Aussage und strukturierten Daten
- Häufigkeit der Relation in unabhängigen Dokumenten
- Kontextkohärenz mit anderen bekannten Relationen
Beispiel:
Die Aussage „Berlin ist die Hauptstadt von Deutschland" erscheint in zahllosen Quellen mit identischer Struktur – sie erhält daher einen nahezu maximalen Vertrauenswert.
Eine seltene Behauptung („Berlin ist älter als Rom") hätte dagegen einen geringen Score und würde nur schwach gewichtet oder verworfen.
Google kombiniert so maschinelles Lernen mit semantischer Konsistenzprüfung. Je stabiler und redundanter eine Relation, desto größer ihre Sichtbarkeit im Knowledge Graph.
8. Dynamik und Aktualisierung
Beziehungen zwischen Entitäten sind nicht statisch. Sie ändern sich mit politischen, gesellschaftlichen oder wissenschaftlichen Entwicklungen.
Der Knowledge Graph speichert daher auch zeitabhängige Relationen.
Beispiel:
Vereinigtes Königreich → Mitglied von → Europäische Union (1973–2020)Nach dem Austritt bleibt die Relation historisch bestehen, wird aber nicht mehr als aktuell markiert.
Zeitliche Qualifikatoren
Wikidata ermöglicht diese Zeitmarkierungen über Qualifikatoren wie start time und end time.
So kann Google sowohl gegenwärtige als auch vergangene Zustände korrekt darstellen.
9. Bedeutung für semantische SEO
Für semantische SEO ist die Logik der Verknüpfung zentral.
Jede Website, die präzise Relationen sichtbar macht, stärkt ihre semantische Position.
Konkrete Auswirkungen
Strukturierte Daten: JSON-LD-Markup mit klaren Entitätsverweisen (Person, Organisation, Ort).
Beispiel:
{
"@context": "https://schema.org",
"@type": "Person",
"name": "Marie Curie",
"worksFor": {
"@type": "Organization",
"name": "Sorbonne"
}
}Kohärente Sprache: Konsistente Verwendung von Begriffen und Kontexten.
Interne Verlinkungen: Semantisch nachvollziehbare Beziehungen zwischen Seiten – nicht nur thematisch, sondern konzeptuell.
Externe Bezüge: Einbindung zu relevanten Entitäten (z. B. offizielle Institutionen oder Werke in Wikidata).
Suchsysteme bewerten Inhalte zunehmend danach, ob sie Bedeutungsketten aufbauen können – also nachvollziehbare Beziehungen zwischen Themen, Autoren und Quellen.
Wer seine Inhalte semantisch verknüpft, wird nicht nur gefunden, sondern verstanden.
10. Herausforderungen und Grenzen
Die Verknüpfung von Entitäten ist ein komplexer Prozess, der an natürliche Sprache stößt.
Typische Probleme
Synonyme: Verschiedene Begriffe für dieselbe Entität („Auto", „Fahrzeug", „Pkw").
Mehrdeutigkeit: Ein Wort mit mehreren Bedeutungen („Jaguar" als Tier oder Automarke).
Beispiel gescheiterter Disambiguierung:
Wenn ein Text „Paris Hilton besucht" erwähnt, könnte ein System fälschlicherweise die Stadt Paris als Entität erkennen, obwohl die Person Paris Hilton gemeint ist.
Google löst dies durch Kontextanalyse: Erscheint „Hotel" im Text, steigt die Wahrscheinlichkeit für die Person. Erscheint „Frankreich", für die Stadt.
Fehlende Struktur: Texte ohne klare Satzbeziehungen erschweren maschinelles Verständnis.
Kulturelle Unterschiede: Relationen wie „Teil von Europa" können je nach Perspektive variieren.
Deshalb stützt sich der Knowledge Graph immer auf redundante, unabhängige Bestätigungen. Wissen gilt erst dann als stabil, wenn es von mehreren Quellen und Modellen zugleich bestätigt wird.
11. Fazit – Bedeutung entsteht durch Verbindung
Der Google Knowledge Graph ist kein Lexikon, sondern ein lebendiges Beziehungsnetz.
Er bildet nicht nur Entitäten ab, sondern die Art, wie sie sich zueinander verhalten.
Jede Relation ist ein semantischer Faden im Geflecht des Wissens.
Für Suchmaschinen zählt nicht mehr, wie oft etwas erwähnt wird, sondern wie sinnvoll es mit anderem verbunden ist.
Für Autoren und Marken bedeutet das: Semantische Autorität entsteht durch Präzision, Klarheit und Verknüpfung – nicht durch Häufigkeit.
Im semantischen Zeitalter gilt:
Wer Bedeutung schafft, wird verlinkt.
Wer Bedeutung verbindet, wird verstanden.
Visuelles Beispiel: Wie Tripel funktionieren
Eine minimale Wissenseinheit: Subjekt → Prädikat → Objekt
Semantische Nähe im Vektorraum
Entitäten mit ähnlicher Bedeutung liegen im semantischen Raum näher beieinander.
Mozart ist näher bei Komponist als bei Physiker.
Über den Autor
Marcus A. Volz ist Wirtschaftswissenschaftler, Linguist und Berater für semantische SEO. Er analysiert, wie Suchmaschinen Bedeutung verstehen und wie Marken durch semantische Klarheit sichtbar werden. Als Gründer von eLengua verbindet er ökonomisches Denken mit linguistischer Präzision, um Unternehmen im Zeitalter der KI-Suche strategisch zu positionieren. Sein Fokus liegt auf Entity SEO, semantischer Architektur und der Optimierung von Markenidentitäten in generativen Systemen.
Häufig gestellte Fragen (FAQ)
Was sind Tripel und warum sind sie wichtig?
Tripel sind die Grundbausteine des semantischen Webs mit der Struktur Subjekt-Prädikat-Objekt (z. B. „Isaac Newton – schrieb – Principia Mathematica"). Sie ermöglichen es Maschinen, Beziehungen zwischen Entitäten zu verstehen und maschinenlesbare Bedeutung aus Texten zu extrahieren.
Wie erkennt Google Beziehungen zwischen Entitäten?
Google analysiert sprachliche Strukturen (Verben, Präpositionen, Satzbau), statistische Muster (gemeinsames Auftreten in Dokumenten) und semantische Kontexte. Maschinelle Modelle extrahieren Relationen unabhängig von Wortstellung oder Passivformen.
Was ist semantische Nähe?
Semantische Nähe entsteht, wenn zwei Begriffe überdurchschnittlich häufig in ähnlichen Kontexten erscheinen. Google modelliert dies in Vektorräumen, wo der Abstand zwischen Entitäten ihre Bedeutungskorrelation widerspiegelt (z. B. liegt „Mozart" näher bei „Komponist" als bei „Astronom").
Welche Arten von Relationen gibt es im Knowledge Graph?
Der Knowledge Graph unterscheidet hierarchische (Zugehörigkeit), funktionale (Rollen/Tätigkeiten), temporale (Zeiträume) und kausale (Ursache-Wirkung) Relationen. Jeder Typ folgt eigenen logischen Regeln und erfordert unterschiedliche Validierungsgrade.
Wie validiert Google die Zuverlässigkeit von Relationen?
Google vergibt einen Confidence Score basierend auf Quellenanzahl und -qualität, Übereinstimmung zwischen Sprache und strukturierten Daten, Häufigkeit in unabhängigen Dokumenten und Kontextkohärenz mit bekannten Relationen. Nur stabile, redundante Relationen werden prominent im Knowledge Graph dargestellt.
Können Relationen im Knowledge Graph sich ändern?
Ja, der Knowledge Graph speichert zeitabhängige Relationen mit Qualifikatoren wie „start time" und „end time". Historische Beziehungen bleiben dokumentiert, werden aber nicht mehr als aktuell markiert (z. B. „Vereinigtes Königreich → Mitglied von → EU (1973–2020)").
Wie kann ich meine Website für Entity Linking optimieren?
Verwende strukturierte Daten (JSON-LD) mit klaren Entitätsverweisen, pflege konsistente Begriffe, schaffe semantisch nachvollziehbare interne Verlinkungen und verweise auf relevante externe Entitäten in Wikidata. Baue Bedeutungsketten zwischen Themen, Autoren und Quellen auf.
Was passiert bei mehrdeutigen Begriffen wie „Paris"?
Google nutzt Kontextanalyse zur Disambiguierung. Erscheinen Begriffe wie „Hotel" im Text, erhöht sich die Wahrscheinlichkeit für „Paris Hilton". Erscheint „Frankreich", für die Stadt Paris. Das System gleicht sprachliche Hinweise mit bekannten Relationen im Knowledge Graph ab.