
Zusammenfassung
Verfasst von Marcus A. Volz. Bedeutung entsteht nicht aus isolierten Begriffen, sondern aus ihren Beziehungen. Die drei fundamentalen Relationen isA, partOf und relatedTo bilden das unsichtbare Gewebe, das Wissen für Maschinen verständlich macht – von Wikipedia bis zum Google Knowledge Graph.
Relationen: isA, partOf, relatedTo – Die drei Grundfäden semantischer Bedeutung
Einleitung – Bedeutung durch Beziehung
Wenn man über „Bedeutung" spricht, denkt man meist an Wörter, Konzepte oder Entitäten. Doch Bedeutung entsteht nicht allein aus Dingen, sondern aus ihren Beziehungen.
Ein Begriff wie „Granada" gewinnt erst dann Tiefe, wenn klar ist, dass es eine Stadt ist (isA), dass sie zu Andalusien gehört (partOf), und dass sie mit Themen wie Kultur oder Flamenco in Verbindung steht (relatedTo).
Diese Relationen bilden das unsichtbare Gewebe, das Wissen für Maschinen verständlich macht.
Ohne Relationen wären Suchmaschinen, Wissensgraphen und künstliche Intelligenz blind. Sie könnten Fakten sammeln, aber keine Zusammenhänge erkennen. Relationen sind das, was aus Daten Bedeutung macht – sie verbinden die Punkte zwischen Entitäten und erzeugen die semantische Struktur, die das Web der Bedeutung zusammenhält.
1. Warum Beziehungen Bedeutung schaffen
In der Semantik ist Wissen immer relational. Kein Konzept existiert isoliert. Eine Stadt ist nur als Teil einer Region denkbar, eine Person nur in einem sozialen oder historischen Kontext.
Diese Verknüpfungen sind nicht nur dekorativ, sondern essenziell: Sie bestimmen, wie wir – und Maschinen – Informationen verstehen, kategorisieren und wiederfinden.
Während Menschen diese Zusammenhänge intuitiv erfassen, brauchen Maschinen formale Strukturen, um sie zu interpretieren. Hier kommen Ontologien ins Spiel. Sie definieren Entitäten, deren Eigenschaften – und eben auch deren Beziehungen.
Die Art, wie diese Beziehungen beschrieben sind, entscheidet darüber, ob ein System nur „Texte durchsucht" oder tatsächlich „Bedeutung versteht".
Die drei wichtigsten Beziehungstypen, die in fast allen Ontologien vorkommen, sind isA, partOf und relatedTo. Sie bilden die Grundlage jedes semantischen Modells – von Wikipedia bis zum Google Knowledge Graph.
2. Was sind semantische Relationen?
Eine semantische Relation ist eine Verbindung zwischen zwei Konzepten, die Bedeutung trägt. Während Syntax die Form beschreibt, beschreibt Semantik die Beziehung zwischen Ideen.
Beispiel
Wenn man sagt „Die Alhambra liegt in Granada", dann ist „liegt in" die Relation, die den Bedeutungszusammenhang herstellt.
Solche Relationen sind kein Zusatzwissen, sondern der eigentliche Kern von Bedeutung. Ohne sie gäbe es nur unverbundene Fragmente. In einer Ontologie sind sie so definiert, dass Maschinen logische Schlüsse ziehen können:
Wenn Granada partOf Andalusien
und Andalusien partOf Spanien,
dann Granada partOf Spanien.Maschinen lernen also nicht nur, dass Dinge existieren, sondern auch, wie sie zueinander stehen.
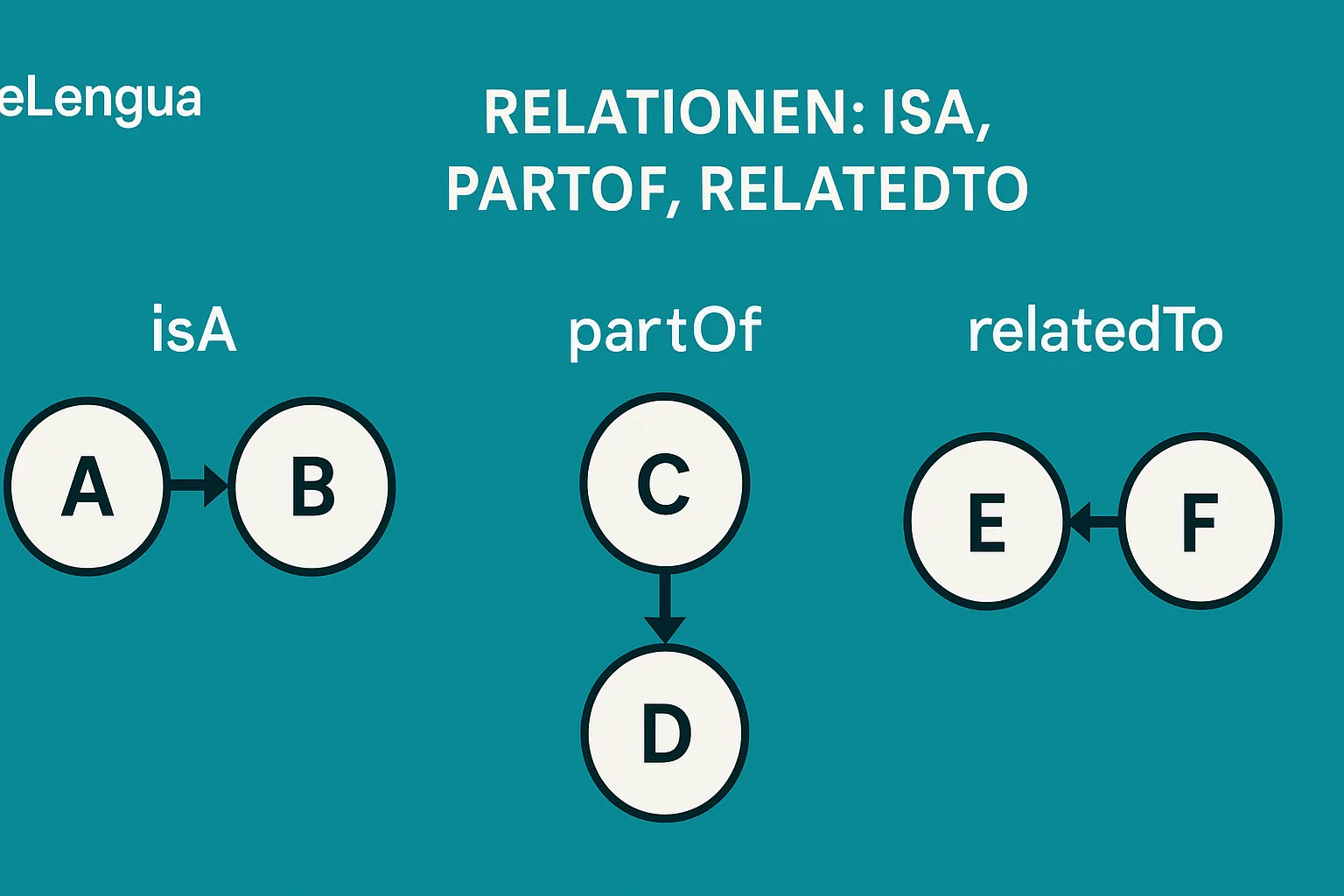
3. Die drei Kernrelationen: isA, partOf, relatedTo
Diese drei Relationen bilden das Grundgerüst semantischer Modelle. Sie sind universell, unabhängig vom Themengebiet, und lassen sich auf alles anwenden – von Biologie bis Suchmaschinenoptimierung.
3.1 isA – Die Hierarchierelation
Die isA-Relation beschreibt die Zugehörigkeit eines Konzepts zu einer übergeordneten Klasse. Sie ordnet Dinge hierarchisch ein und schafft damit den logischen Rahmen einer Ontologie.
Beispiele
Katze isA TierMadrid isA StadtSEO isA Marketingstrategie
Diese Relation erzeugt Baumstrukturen. Sie ermöglicht Verallgemeinerungen und Schlussfolgerungen: Wenn „Katze" ein „Tier" ist, dann gelten alle tierbezogenen Eigenschaften auch für Katzen.
In der semantischen Suche ist isA entscheidend, um Themen zu erweitern oder einzugrenzen. Wenn ein Nutzer nach „Tieren in Andalusien" sucht, versteht Google, dass eine Seite über „Iberische Luchse" relevant ist, weil Luchs isA Tier.
Im Kontext von Schema.org ist diese Relation über das Attribut @type umgesetzt. Eine Seite mit @type: LocalBusiness signalisiert der Suchmaschine, dass es sich um eine Unterklasse von Organization handelt.
isA-Beziehungen sind die Hierarchieebenen des Wissens – sie schaffen Ordnung in der Vielfalt.
3.2 partOf – Die Teil-Ganzes-Beziehung
Während isA Klassenzugehörigkeit ausdrückt, beschreibt partOf strukturelle Zugehörigkeit. Sie sagt aus, dass etwas Teil eines größeren Ganzen ist.
Beispiele
Granada partOf AndalusienAndalusien partOf SpanienKapitel partOf BuchZahn partOf Mund
Diese Relation ist asymmetrisch: Wenn A Teil von B ist, gilt nicht automatisch das Umgekehrte. Sie eignet sich hervorragend für räumliche, organisatorische oder funktionale Strukturen.
In der Geografie beschreibt partOf politische oder topografische Ebenen. In der Biologie anatomische Zusammenhänge. In der SEO kann sie verwendet werden, um Webseiten logisch zu strukturieren.
Praxisbeispiel SEO
Die Seite „Alhambra Granada" ist partOf des Clusters „Sehenswürdigkeiten Andalusien".
Suchmaschinen können daraus schließen, dass diese Inhalte kontextuell zusammengehören.
Auf technischer Ebene lässt sich das als RDF-Triple ausdrücken:
Granada → partOf → Andalusien
Andalusien → partOf → Spanien
OWL kann daraus folgern:
Granada → partOf → SpanienDiese logische Transitivität ist der Grund, warum Maschinen über einzelne Fakten hinaus Bedeutung ableiten können.
Die drei Relationen visualisiert
Jede Relation hat ihre eigene Logik: isA schafft Hierarchien, partOf strukturiert Teile zu Ganzen, relatedTo verbindet assoziativ.
4. Wie Relationen maschinenlesbar werden
Suchmaschinen und KI-Systeme brauchen standardisierte Formen, um Relationen zu verstehen. Die Basis ist das sogenannte RDF-Tripel:
Subjekt – Prädikat – ObjektBeispiele
Alhambra – locatedIn – Granada
Granada – partOf – Andalusien
Andalusien – partOf – SpanienDiese einfache Struktur macht Wissen maschinenlesbar. RDF ist dabei die Grammatik, OWL die Logik, und Schema.org das Vokabular.
Suchmaschinen speichern nicht Seiten, sondern Aussagen. Der Google Knowledge Graph ist letztlich eine Sammlung solcher Tripel – Milliarden kleiner Beziehungseinheiten, die zusammen das semantische Weltbild der Maschine bilden.
SEO-Texte, die Relationen explizit abbilden – etwa durch strukturierte Daten oder semantisch klare Verknüpfungen –, werden dadurch verständlicher, zuverlässiger und besser kontextualisiert.
5. Warum Relationen für semantische SEO entscheidend sind
In der Keyword-basierten SEO zählte früher die Häufigkeit eines Begriffs. Heute zählt die Bedeutungsarchitektur. Relationen sind die unsichtbaren Fäden, die Kontext, Tiefe und Relevanz erzeugen.
isA-Beziehungen
Helfen, Inhalte zu kategorisieren
Beispiel: Spanischkurs isA Sprachkurs
partOf-Beziehungen
Helfen, Cluster zu strukturieren
Beispiel: Onlinekurs partOf MundoDele
relatedTo-Beziehungen
Schaffen thematische Kohärenz
Beispiel: Spanischlernen relatedTo Reisen in Spanien
Diese Logik lässt sich auch in internen Verlinkungen abbilden. Wenn eine Seite über „Granada" auf „Andalusien" verweist, ist das keine zufällige Verbindung – es ist eine partOf-Relation, die semantische Tiefe schafft.
Suchmaschinen werten solche Strukturen aus. Eine konsistente interne Verlinkung kann also als ontologische Beziehung gelesen werden. Wer seine Website wie eine kleine Ontologie denkt, baut semantische Autorität auf – nicht durch Masse, sondern durch Bedeutung.
6. Praxisbeispiel: Semantische Website-Struktur
Wie setzt man diese Relationen konkret um? Hier ein Beispiel aus der Praxis einer Reise-Website:
Szenario: Content-Cluster "Andalusien"
Zentrale Pillar-Page: „Reisen nach Andalusien"
Cluster-Seiten mit expliziten Relationen:
- „Granada besuchen" →
Granada partOf Andalusien - „Alhambra" →
Alhambra locatedIn Granada+Alhambra isA Sehenswürdigkeit - „Flamenco in Sevilla" →
Flamenco relatedTo Andalusien - „Wandern in Sierra Nevada" →
Sierra Nevada partOf Andalusien
Interne Verlinkung:
- Von „Reisen nach Andalusien" zu allen Cluster-Seiten (Hub-Struktur)
- Von „Granada" zu „Alhambra" (Teil-Struktur)
- Von „Flamenco" zu „Sevilla" und „Kultur" (assoziative Links)
Strukturierte Daten (Schema.org):
{
"@type": "TouristAttraction",
"name": "Alhambra",
"location": {
"@type": "Place",
"name": "Granada",
"containedInPlace": {
"@type": "AdministrativeArea",
"name": "Andalusien"
}
}
}Durch diese Struktur entsteht ein semantisches Netz, das Suchmaschinen nicht nur verstehen, sondern als kohärentes Wissensgebiet bewerten können.
7. Relationen im Knowledge Graph und in KI-Systemen
Im Google Knowledge Graph oder in OpenAI-Modellen sind Relationen keine abstrakten Ideen, sondern messbare Signale. Sie haben Gewicht, Richtung und Relevanz.
Google bewertet Relationen nach drei Kriterien:
- Häufigkeit: Wie oft wird eine Beziehung in glaubwürdigen Quellen bestätigt?
- Autorität: Stammt die Relation aus vertrauenswürdigen Datenquellen?
- Kontextkonsistenz: Passt die Beziehung zum semantischen Umfeld?
Beispiel: Eine Beziehung wie Paella relatedTo Valencia ist stärker, weil sie in vielen glaubwürdigen Quellen vorkommt.
LLMs (Large Language Models) funktionieren anders:
Sie repräsentieren Relationen als Vektoren. Sie messen semantische Nähe nicht symbolisch, sondern statistisch – nach der Häufigkeit gemeinsamer Kontexte.
Damit verbinden sich zwei Welten:
- Symbolische Semantik (Ontologien, explizit modelliert)
- Distributionale Semantik (KI-Modelle, implizit gelernt)
Je besser beide Ebenen übereinstimmen, desto konsistenter wird maschinelles Verständnis. Für SEO heißt das: Inhalte, die klare Relationen widerspiegeln, sind sowohl für Suchmaschinen als auch für LLMs verständlicher und zitierfähiger.
8. Herausforderungen bei der Modellierung von Relationen
So einfach Relationen klingen, so komplex ist ihre Umsetzung. Drei Probleme treten immer wieder auf:
1. Mehrdeutigkeit
Ein Wort wie „Bank" kann Möbelstück oder Finanzinstitut bedeuten. Ohne Kontext ist die Relation wertlos.
Lösung: Disambiguierte Entitäten mit eindeutiger ID (z. B. Wikidata-Q-Nummern).
2. Kontextabhängigkeit
„Teil von" kann räumlich, logisch oder zeitlich gemeint sein.
Lösung: Relationale Typisierung (z. B. spatialPartOf, memberOf, phaseOf).
3. Dynamik
Relationen verändern sich – Firmen fusionieren, Regionen werden neu definiert, Bedeutungen wandeln sich.
Lösung: Versionierte Ontologien und hybride Modelle, die mit LLMs aktualisiert werden.
Semantik ist also nie statisch. Sie ist ein lebendiges System, das sich mit der Welt verändert.
9. Fazit – Bedeutung entsteht durch Beziehung
In der semantischen Welt ist nichts isoliert. Bedeutung ist ein Netz, kein Punkt.
isA, partOf und relatedTo sind die drei Grundfäden, aus denen dieses Netz gewebt wird.
Sie machen Wissen erklärbar, skalierbar und erweiterbar – für Menschen, Maschinen und Suchalgorithmen gleichermaßen.
Ontologien ohne Relationen sind wie Wörter ohne Grammatik. Erst durch Beziehungen entsteht Sinn.
Für die semantische SEO heißt das: Wer Relationen sichtbar macht – in Texten, Daten und internen Strukturen –, schafft Relevanz, die über Keywords hinausgeht.
Daten sind der Stoff, Relationen sind die Bedeutung.
Über den Autor
Marcus A. Volz ist Wirtschaftswissenschaftler, Linguist und Berater für semantische SEO und generative Sichtbarkeit. Er analysiert, wie Suchmaschinen und KI-Systeme Bedeutung verstehen und wie Marken durch semantische Klarheit sichtbar werden. Als Gründer von eLengua verbindet er ökonomisches Denken mit linguistischer Präzision, um Unternehmen im Zeitalter der KI-Suche strategisch zu positionieren.
Häufig gestellte Fragen (FAQ)
Was sind semantische Relationen?
Semantische Relationen sind Verbindungen zwischen zwei Konzepten, die Bedeutung tragen. Sie beschreiben, wie Entitäten zueinander stehen – etwa durch Hierarchie (isA), Teil-Ganzes-Beziehungen (partOf) oder assoziative Verknüpfungen (relatedTo).
Was bedeutet isA in der Semantik?
isA beschreibt die Zugehörigkeit zu einer übergeordneten Klasse. Beispiel: "Katze isA Tier" bedeutet, dass Katze eine Unterklasse von Tier ist. Diese Relation schafft hierarchische Strukturen und ermöglicht Verallgemeinerungen.
Wie unterscheiden sich partOf und isA?
isA beschreibt Klassenzugehörigkeit (hierarchisch), während partOf strukturelle Zugehörigkeit ausdrückt. "Madrid isA Stadt" bedeutet Madrid gehört zur Kategorie Stadt. "Madrid partOf Spanien" bedeutet Madrid ist geografisch Teil von Spanien.
Was ist die relatedTo-Relation?
relatedTo beschreibt assoziative Beziehungen ohne feste Hierarchie oder Struktur. Sie verbindet thematisch verwandte Konzepte – etwa "Flamenco relatedTo Andalusien". Diese Relation ist symmetrisch und die flexibelste Form semantischer Verknüpfung.
Wie werden Relationen maschinenlesbar?
Durch RDF-Tripel: Subjekt-Prädikat-Objekt. Beispiel: "Granada – partOf – Andalusien". Standards wie RDF (Grammatik), OWL (Logik) und Schema.org (Vokabular) machen diese Beziehungen für Suchmaschinen verständlich.
Warum sind Relationen für SEO wichtig?
Relationen schaffen semantische Tiefe und Kontext. Sie helfen Suchmaschinen zu verstehen, wie Inhalte zusammenhängen. Websites, die Relationen explizit abbilden (durch strukturierte Daten und interne Verlinkung), werden besser verstanden und kontextualisiert.
Wie nutzt der Google Knowledge Graph Relationen?
Der Knowledge Graph speichert Millionen von RDF-Tripeln – kleine Beziehungseinheiten zwischen Entitäten. Er bewertet Relationen nach Häufigkeit, Autorität und Kontextkonsistenz, um ein semantisches Weltbild aufzubauen.
Wie implementiere ich Relationen auf meiner Website?
Durch drei Maßnahmen: (1) Semantisch logische interne Verlinkung nach Relationstypen, (2) Strukturierte Daten mit Schema.org zur expliziten Auszeichnung, (3) Content-Clustering nach ontologischen Prinzipien (Pillar-Cluster-Modell).
Was sind die größten Herausforderungen bei Relationen?
Drei Hauptprobleme: (1) Mehrdeutigkeit – Begriffe können mehrere Bedeutungen haben, (2) Kontextabhängigkeit – Relationen können unterschiedlich interpretiert werden, (3) Dynamik – Beziehungen verändern sich mit der Zeit und erfordern Aktualisierung.