
Zusammenfassung
Semantisches SEO erreicht seinen strategischen Wendepunkt dort, wo Bedeutung nicht mehr nur interpretiert, sondern explizit festgeschrieben wird. Während NLP-Systeme analysieren und Embeddings Ähnlichkeiten berechnen, schaffen Entity-Graphen stabile Identitäten und nachvollziehbare Beziehungen. Dieser Artikel erklärt, wie Entity-Extraktion funktioniert, warum Graph-Denken für SEO unverzichtbar ist und wie entsprechende Tools sinnvoll eingesetzt werden.
Entity-Extraktion & Graph-Tools
Bedeutung explizit modellieren
Warum Entity-Extraktion der Wendepunkt im semantischen SEO ist
In frühen SEO-Modellen genügte es, Begriffe zu optimieren. In modernen Systemen reicht es nicht einmal mehr, Themen sauber abzudecken. Entscheidend ist, welche Entitäten existieren, wie eindeutig sie sind und in welchem Bedeutungsnetz sie stehen.
Suchmaschinen und KI-Systeme arbeiten langfristig nicht mit Texten, sondern mit Referenzen: eindeutigen Konzepten, die über verschiedene Dokumente, Sprachen und Kontexte hinweg stabil bleiben.
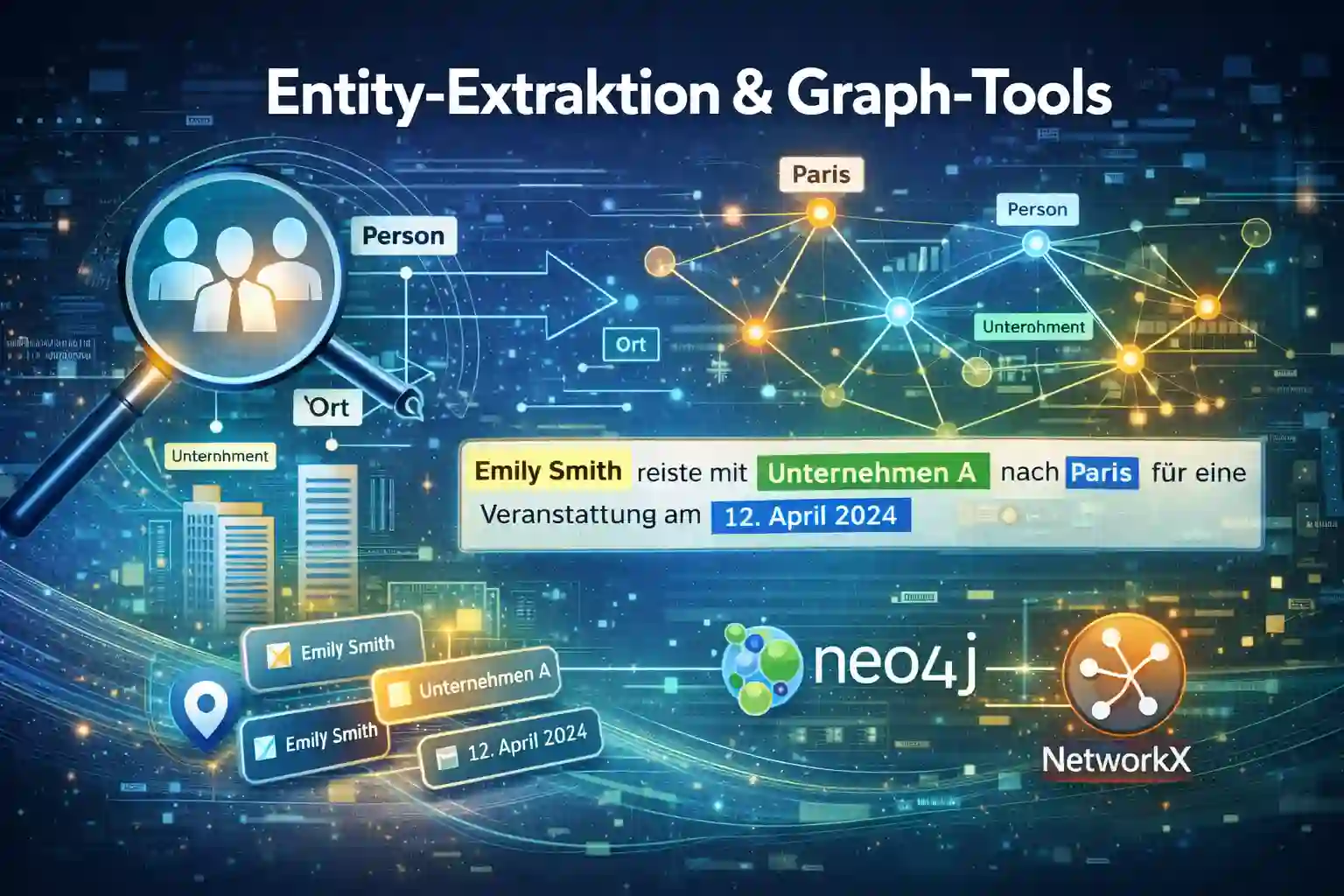
Entity-Extraktion ist der Prozess, mit dem diese Konzepte aus unstrukturierten Texten identifiziert und in eine strukturierte Wissensform überführt werden.
Was ist eine Entität? Eine SEO-relevante Definition
Eine Entität ist ein eindeutig identifizierbares Konzept, das unabhängig von seiner textlichen Darstellung existiert. Das kann eine Person, ein Unternehmen, ein Ort, ein Produkt, ein Werk oder auch ein abstraktes Konzept sein.
Wichtig ist die Abgrenzung:
- Ein Begriff ist eine Zeichenfolge
- Eine Entität ist eine Bedeutungseinheit mit Identität
Beispiel: Begriff vs. Entität
Begriff: „Apple"
Problem: Mehrdeutig – kann bedeuten: Frucht, Apple Inc. (Unternehmen), Apple Records (Plattenlabel), Apfel (deutsche Übersetzung)
Entität: „Apple Inc." mit Wikidata-ID Q312
Eindeutig: Bezeichnet immer das Technologieunternehmen, gegründet 1976, CEO Tim Cook, Hauptsitz Cupertino
„Apple" als Wort ist mehrdeutig. „Apple Inc." als Entität ist eindeutig. Für SEO ist diese Unterscheidung zentral, da nur Entitäten referenzierbar, verknüpfbar und langfristig stabil sind.
Wie Entity-Extraktion technisch funktioniert
Entity-Extraktion besteht aus mehreren aufeinanderfolgenden Schritten:
1. Named Entity Recognition (NER)
Erkennung potenzieller Entitäten im Text (z. B. Personen, Organisationen, Orte).
2. Entity Linking (Disambiguierung)
Zuordnung dieser Textstellen zu einer konkreten Entität – etwa in einer Wissensbasis.
3. Kontextuelle Validierung
Prüfung, ob die Zuordnung im inhaltlichen Zusammenhang korrekt ist.
Beispiel: Entity-Extraktion Schritt für Schritt
Text: „Apple kündigte heute ein neues iPhone an. Tim Cook präsentierte die Features in Cupertino."
Schritt 1 – NER erkennt:
- „Apple" → Organization
- „iPhone" → Product
- „Tim Cook" → Person
- „Cupertino" → Location
Schritt 2 – Entity Linking:
- „Apple" → Q312 (Wikidata ID für Apple Inc.)
- „iPhone" → Q2766 (Wikidata ID für iPhone-Produktlinie)
- „Tim Cook" → Q19323 (CEO von Apple Inc.)
- „Cupertino" → Q48400 (Stadt in Kalifornien, Hauptsitz von Apple)
Schritt 3 – Kontextuelle Validierung:
Kontext bestätigt: Es geht um Apple Inc. (Technologie), nicht um die Frucht oder Apple Records. Die Relationen sind konsistent: Tim Cook ist CEO von Apple Inc., Cupertino ist Hauptsitz.
Code-Beispiel: Entity-Erkennung mit spaCy
Moderne Systeme kombinieren statistische Modelle, linguistische Regeln und Wissensdatenbanken. Open-Source-Frameworks wie spaCy oder Stanford NLP werden häufig für NER eingesetzt, während externe Referenzen (Wikidata, DBpedia) für das Linking nötig sind.
Typische Probleme bei der Entity-Extraktion
In der Praxis stößt automatische Extraktion schnell an Grenzen:
- Mehrdeutigkeit: gleiche Begriffe, unterschiedliche Entitäten
- Lokale Marken: außerhalb globaler Wissensbasen unbekannt
- Fachterminologie: nicht standardisiert oder kontextabhängig
- Sprachvarianten: unterschiedliche Schreibweisen, Abkürzungen
Beispiel: Mehrdeutigkeit in der Praxis
Text: „Orange plant Expansion in Deutschland."
Problem: Ist „Orange" die Telekom-Firma (Orange S.A.), die Frucht, die Farbe oder die Stadt in Frankreich?
Entity-Extraktion ohne Kontext:
- Mögliche Fehlerkennung: „Orange" → Q13191 (Frucht)
Entity-Extraktion mit Kontext:
- Kontext-Signale: „plant Expansion", „Deutschland" → geschäftlicher Kontext
- Korrekte Zuordnung: „Orange" → Q1431486 (Orange S.A., Telekommunikationsunternehmen)
Gerade im SEO-Kontext ist daher klar: Automatische Extraktion liefert Vorschläge, keine verlässlichen Entitätsmodelle. Menschliche Validierung bleibt notwendig.
Implizite vs. explizite Entitäten
Ein entscheidender Unterschied für semantisches SEO ist der zwischen impliziten und expliziten Entitäten.
- Implizite Entitäten existieren nur im Text
- Explizite Entitäten existieren als strukturierte Objekte mit ID
Suchmaschinen können implizite Entitäten interpretieren, aber nur explizite Entitäten persistieren. Erst durch Strukturierung entstehen stabile Signale über mehrere Inhalte hinweg.
SEO-relevant wird eine Entität daher erst dann, wenn sie modelliert, referenziert und konsistent verwendet wird.
Graph-Denken: Warum Relationen wichtiger sind als Listen
Entitäten entfalten ihre Bedeutung nicht isoliert, sondern durch Beziehungen. Ein einzelner Eintrag ist wertlos ohne Kontext.
Graph-Modelle bilden Wissen als Netzwerke ab. Die grundlegende Logik lautet:
Subjekt – Prädikat – Objekt
Beispiel: Graph-Relationen erweitern Bedeutung
Einfache Relation:
„Marcus A. Volz" → ist Gründer von → „eLengua"
Graph erweitern:
- „Marcus A. Volz" → ist Gründer von → „eLengua"
- „Marcus A. Volz" → hat Expertise in → „Semantisches SEO"
- „Marcus A. Volz" → hat Expertise in → „Entity-Extraktion"
- „eLengua" → bietet Service → „Entity-basierte Content-Strategien"
- „eLengua" → hat Standort in → „Deutschland"
- „eLengua" → ist spezialisiert auf → „Semantisches SEO"
Ergebnis für Suchmaschinen:
Aus diesen Relationen lässt sich ableiten: „Marcus A. Volz" ist Experte für „Semantisches SEO" und „Entity-Extraktion", verbunden mit „eLengua" als Organisation. Autorität und Themenrelevanz werden durch Relationen erkennbar, nicht durch isolierte Erwähnungen.
Diese Relation ist bedeutungsvoller als jede Keyword-Liste. Der Unterschied zu Tabellen ist fundamental: Tabellen speichern Daten, Graphen speichern Bedeutung.
Arten von Graph-Systemen im SEO-Kontext
Im semantischen SEO begegnen drei grundlegende Graph-Typen:
Knowledge Graphs
Stark strukturierte, ontologische Modelle mit klaren Typen und Relationen. Beispiel: Wikidata, Google Knowledge Graph.
Property Graphs
Flexiblere Graphen mit Attributen an Knoten und Kanten. Beispiel: Neo4j, Amazon Neptune.
Hybride Modelle
Kombinationen aus Graph-Struktur und Vektor-Suche. Beispiel: Weaviate (verbindet Embeddings mit semantischem Schema).
Für SEO ist nicht der technische Unterbau entscheidend, sondern die Modellierungslogik.
Graph-Tools: Kategorien statt Tool-Fetisch
Statt einzelne Tools aufzuzählen, ist eine funktionale Einordnung sinnvoll:
- Extraktionstools: Identifizieren potenzieller Entitäten (spaCy, Stanford NLP, Google NLP API)
- Linking-Tools: Abgleich mit Wissensbasen (Wikidata API, DBpedia Spotlight)
- Graph-Datenbanken: Speicherung und Abfrage (Neo4j, Amazon Neptune, Weaviate)
- Visualisierungstools: Analyse und Pflege (Gephi, Neo4j Browser, Graph-visualization-libraries)
Externe Wissensbasen wie Wikidata dienen häufig als Referenz, ersetzen jedoch keine eigene Modellierung.
Eigene Entity-Graphen für SEO aufbauen
Ein sinnvoller SEO-Graph entsteht nicht automatisch. Er folgt klaren Prinzipien:
- Relevanz vor Vollständigkeit
- klare Granularität (nicht jede Erwähnung ist eine Entität)
- stabile IDs
- konsistente Benennung über Sprachen hinweg
Beispiel: Falsche vs. richtige Granularität
Zu grob:
Jeder Artikel über „PostgreSQL" wird als „PostgreSQL (Datenbank)" getaggt – keine Differenzierung zwischen Performance, Installation, Security, Backup. Interne Verlinkung wird nicht granular steuerbar.
Zu fein:
Jede Erwähnung von „PostgreSQL 15.2", „PostgreSQL 14.8", „PostgreSQL 13.11" wird als separate Entität modelliert. Der Graph explodiert mit Hunderten von Versionsnummern, kein praktischer Nutzen.
Richtig:
„PostgreSQL" als Hauptentität (Q819114 in Wikidata). Unterthemen wie „PostgreSQL Performance Tuning", „PostgreSQL Security" als separate Entities mit Relation „ist Unterthema von" → PostgreSQL. Versionsnummern als Properties, nicht als separate Entities.
Besonders wichtig ist die Pflege. Ein veralteter oder inkonsistenter Graph schadet mehr, als er nützt.
Verbindung zu Schema.org und strukturierten Daten
Interne Entity-Graphen entfalten ihren SEO-Wert erst, wenn sie nach außen kommuniziert werden. Hier kommt Schema.org ins Spiel.
Schema ist kein Graph-Ersatz, sondern ein Publikationsformat. Es erlaubt, ausgewählte Teile des internen Bedeutungsmodells für Suchmaschinen sichtbar zu machen – typischerweise über JSON-LD.
Beispiel: Interner Graph vs. Schema-Ausgabe
Interner Graph für „eLengua" (500+ Properties):
- Gründungsjahr, Mitarbeiteranzahl, Projekte, Kunden, Awards
- Interne Notizen, Prozesse, Workflows
- Detaillierte Kontakthistorie, Meeting-Protokolle
- Technologie-Stack, verwendete Tools
Schema.org-Ausgabe (8 Properties):
- Name: „eLengua"
- Logo: URL zum Logo
- Adresse: Geschäftsadresse
- Kontaktpunkte: Telefon, E-Mail
- Social-Media-Profile: LinkedIn, Twitter
- Gründer: „Marcus A. Volz"
- Beschreibung: „Semantische SEO-Agentur"
- URL: elengua.com
Grund: Schema.org soll Suchmaschinen informieren, nicht den gesamten internen Wissensstand offenlegen. Relevanz > Vollständigkeit.
Wichtig ist die Trennung: interner Graph (komplex, detailliert), Schema-Ausgabe (reduziert, selektiv).
Praktische SEO-Use-Cases für Entity-Graphen
Richtig eingesetzt unterstützen Entity-Graphen unter anderem:
Use-Case 1: Konsistente interne Verlinkung
Problem: 150 Artikel erwähnen „PostgreSQL", aber nur 60% verlinken zur PostgreSQL-Hub-Seite.
Graph-Analyse:
- Query: Alle Artikel mit Entity „PostgreSQL" (Q819114)
- Ergebnis: 150 Artikel identifiziert
- Check: Welche verlinken intern zu /postgresql-guide/?
- Ergebnis: Nur 90 Artikel (60%)
Aktion: Automatisierte Verlinkungsempfehlungen für die 60 fehlenden Artikel. Interne Verlinkung wird konsistent mit Entity-Erwähnungen.
Use-Case 2: Aufbau nachvollziehbarer Themenautorität
Aufgabe: Zeigen, dass „Marcus A. Volz" Autorität in „Semantisches SEO" hat.
Graph-Modellierung:
- „Marcus A. Volz" → hat geschrieben → 45 Artikel über „Semantisches SEO"
- „Marcus A. Volz" → ist Gründer von → „eLengua"
- „eLengua" → ist spezialisiert auf → „Semantisches SEO"
- „Marcus A. Volz" → hat Expertise in → „Entity-Extraktion", „Knowledge Graphs", „Schema.org"
Schema-Ausgabe: Person-Schema mit „knowsAbout": [„Semantic SEO", „Entity Extraction", „Knowledge Graphs"]
Use-Case 3: Saubere Mehrsprachigkeit
Problem: Deutsche und englische Artikel referenzieren dieselben Konzepte, aber Verlinkung ist inkonsistent.
Graph-Lösung:
- Entity „PostgreSQL" hat Labels in DE („PostgreSQL Datenbank") und EN („PostgreSQL Database")
- Beide Sprachversionen verlinken auf dieselbe Entity-ID
- Automatische Cross-Language-Verlinkung wird möglich
Der Nutzen entsteht nicht durch einzelne Markups, sondern durch kohärente Struktur über viele Inhalte hinweg.
Grenzen und typische Fehlannahmen
Zu den häufigsten Irrtümern zählen:
- „Ein Graph ist ein Rankingfaktor."
- „Automatische Extraktion reicht aus."
- „Mehr Entitäten sind besser."
Entity-Graphen sind strategische Modelle, keine taktischen SEO-Tricks. Ihre Wirkung ist indirekt, langfristig und strukturell.
Fazit: Bedeutung braucht explizite Struktur
Semantisches SEO endet nicht bei Analyse oder Ähnlichkeit. Es beginnt dort, wo Bedeutung explizit modelliert wird. Entity-Extraktion und Graph-Tools liefern dafür das Fundament.
Wer bereit ist, Entitäten sauber zu definieren, Relationen bewusst zu modellieren und Struktur langfristig zu pflegen, schafft nicht nur bessere SEO-Signale – sondern ein belastbares Wissenssystem.
Nächster Schritt: Der nächste Artikel „Open-Source Frameworks" zeigt, welche Frameworks und Bibliotheken für Entity-Extraktion, Graph-Modellierung und semantische Analyse praktisch einsetzbar sind.
Über den Autor
Marcus A. Volz ist Linguist und Spezialist für semantische KI-Systeme bei eLengua. Er analysiert, wie Suchmaschinen und KI-Systeme Bedeutung verstehen – von strukturierten Daten über Entity-Mapping bis zur semantischen Content-Architektur. Seine Arbeit verbindet theoretische Sprachwissenschaft mit praktischer Anwendung in SEO und Content-Strategie.
Interesse an Entity-Graphen für Ihre Content-Strategie?
eLengua unterstützt Unternehmen dabei, Entity-basierte Wissensstrukturen aufzubauen – von Entity-Extraktion über Graph-Modellierung bis zur Schema.org-Integration.
Häufig gestellte Fragen (FAQ)
Was ist Entity-Extraktion?
Entity-Extraktion ist der Prozess, mit dem eindeutige Konzepte aus unstrukturierten Texten identifiziert und in strukturierte Wissensform überführt werden. Sie besteht aus Named Entity Recognition (NER), Entity Linking (Disambiguierung) und kontextueller Validierung.
Was ist der Unterschied zwischen Begriff und Entität?
Ein Begriff ist eine Zeichenfolge, eine Entität ist eine Bedeutungseinheit mit Identität. „Apple" als Wort ist mehrdeutig, „Apple Inc." als Entität ist eindeutig. Nur Entitäten sind referenzierbar, verknüpfbar und langfristig stabil.
Was ist der Unterschied zwischen impliziten und expliziten Entitäten?
Implizite Entitäten existieren nur im Text. Explizite Entitäten existieren als strukturierte Objekte mit ID. Suchmaschinen können implizite Entitäten interpretieren, aber nur explizite Entitäten persistieren. SEO-relevant wird eine Entität erst durch Modellierung, Referenzierung und konsistente Verwendung.
Warum sind Graph-Modelle wichtig für SEO?
Entitäten entfalten ihre Bedeutung durch Beziehungen. Graph-Modelle bilden Wissen als Netzwerke ab nach dem Prinzip Subjekt-Prädikat-Objekt. Graphen speichern Bedeutung, nicht nur Daten. Relationen sind bedeutungsvoller als Keyword-Listen.
Welche typischen Probleme gibt es bei Entity-Extraktion?
Mehrdeutigkeit (gleiche Begriffe, unterschiedliche Entitäten), lokale Marken außerhalb globaler Wissensbasen, nicht standardisierte Fachterminologie und unterschiedliche Sprachvarianten. Automatische Extraktion liefert Vorschläge, keine verlässlichen Entitätsmodelle.
Wie baue ich einen eigenen Entity-Graphen für SEO auf?
Ein sinnvoller SEO-Graph folgt klaren Prinzipien: Relevanz vor Vollständigkeit, klare Granularität (nicht jede Erwähnung ist eine Entität), stabile IDs und konsistente Benennung über Sprachen hinweg. Besonders wichtig ist die Pflege – ein veralteter oder inkonsistenter Graph schadet mehr, als er nützt.
Was ist der Unterschied zwischen internem Graph und Schema.org?
Schema.org ist kein Graph-Ersatz, sondern ein Publikationsformat. Interner Graph: komplex, detailliert, für eigene Analyse. Schema-Ausgabe: reduziert, selektiv, für Suchmaschinen. Schema erlaubt, ausgewählte Teile des internen Bedeutungsmodells sichtbar zu machen.
Sind Entity-Graphen ein Rankingfaktor?
Nein. Entity-Graphen sind strategische Modelle, keine taktischen SEO-Tricks. Ihre Wirkung ist indirekt, langfristig und strukturell. Sie unterstützen nachvollziehbare Themenautorität, konsistente interne Verlinkung und klare Markenprofile.