
Zusammenfassung
Die Vektorsuche ist das Herzstück moderner Such- und Empfehlungssysteme. Sie übersetzt Sprache, Bilder oder Dokumente in mathematische Strukturen – Vektoren – um deren Bedeutung messbar zu machen. Statt auf exakte Wortübereinstimmungen zu reagieren, sucht die Maschine nach semantischer Nähe. Dieser Artikel erklärt, wie aus Text Vektoren werden, wie die Suche im Bedeutungsraum funktioniert und warum semantische Relevanz wichtiger ist als Wortidentität.
Wie Vektorsuche funktioniert
Bedeutung als Vektorraum
1. Sprache als Zahlenraum
In der klassischen Informatik war Sprache immer etwas Problematisches: Wörter sind keine Zahlen, man kann sie nicht addieren oder vergleichen. Erst mit der Einführung der sogenannten Vektordarstellung wurde das möglich.
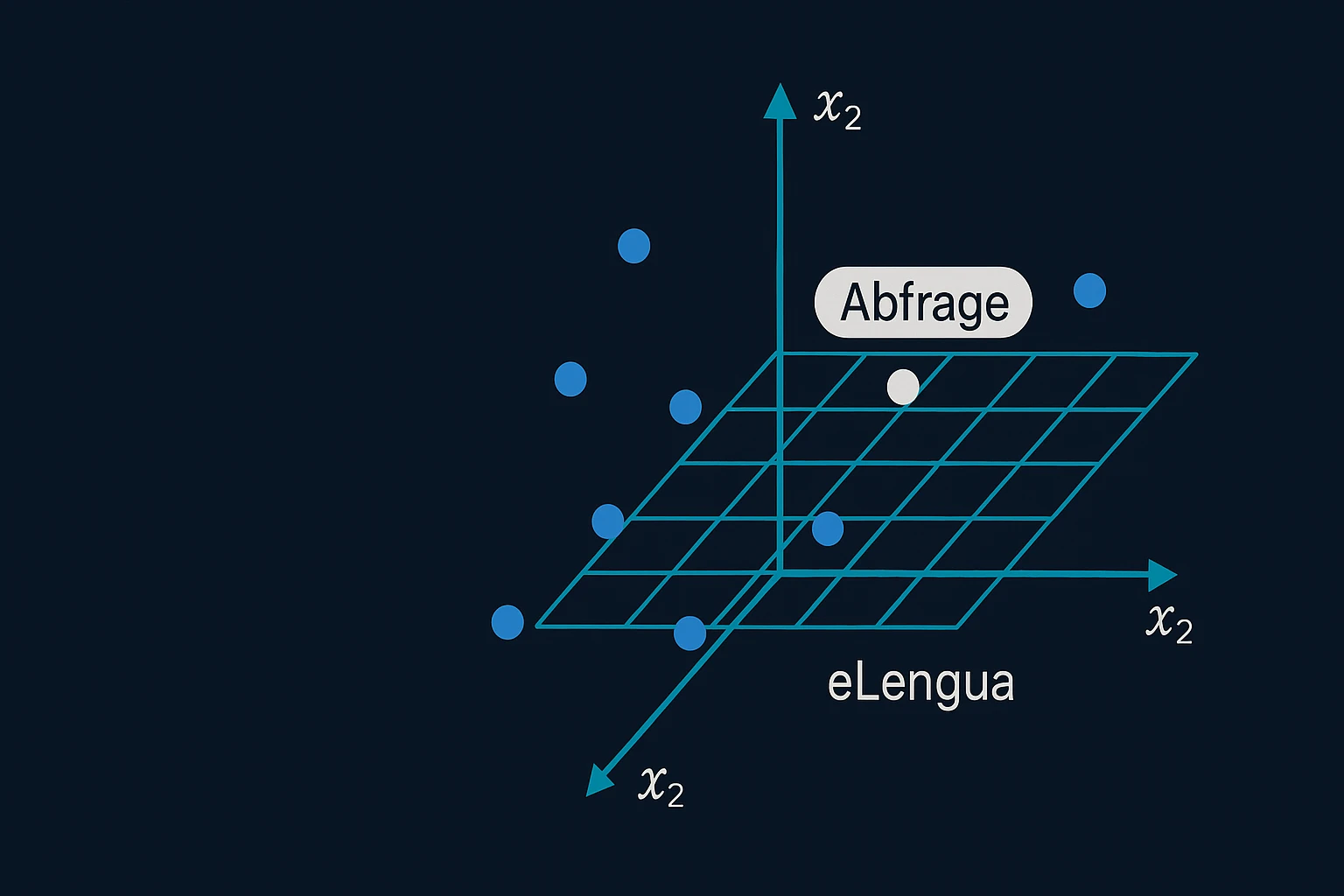
Ein Vektor ist eine Reihe von Zahlen – etwa [0.12, 0.48, -0.37, …]. Jede Zahl repräsentiert eine Dimension, und gemeinsam bilden sie einen Punkt im Raum. Wenn man jedes Wort auf diese Weise abbildet, entsteht ein mehrdimensionaler Bedeutungsraum, in dem semantisch ähnliche Wörter eng beieinanderliegen.
Ein einfaches Beispiel:
„Apfel", „Birne" und „Pfirsich" befinden sich im gleichen Bereich des Raumes, während „Schraube" oder „Auto" weit entfernt liegen.
Diese Nähe ist kein Zufall, sondern das Ergebnis statistischer Muster: Wörter, die in ähnlichen Kontexten vorkommen, erhalten ähnliche Vektoren.
So entsteht ein System, in dem Sprache mathematisch vergleichbar wird – das Fundament der Vektorsuche.
2. Wie aus Text Vektoren werden
Die Umwandlung von Wörtern oder Sätzen in Vektoren geschieht durch Trainingsmodelle, die auf großen Textkorpora basieren. Diese Modelle lernen, welche Wörter häufig gemeinsam auftreten und wie sie sich gegenseitig beeinflussen.
Die bekanntesten Verfahren sind:
Word2Vec: lernt Wortbeziehungen durch das Prinzip „Sag mir, mit wem du sprichst, und ich sage dir, wer du bist". Wenn zwei Wörter oft in ähnlichen Umgebungen vorkommen, werden sie als ähnlich angesehen.
GloVe (Global Vectors): nutzt statistische Zusammenhänge aus der gesamten Textsammlung, um Beziehungen zu berechnen.
BERT & Sentence-BERT: analysieren nicht nur einzelne Wörter, sondern ganze Sätze und ihren Kontext. Sie sind die Grundlage heutiger semantischer Modelle.
Gemini-Embeddings oder OpenAI-Embeddings: moderne Varianten, die auch Mehrdeutigkeit, Sprachrichtung und Bedeutungsnuancen erfassen.
Das Ergebnis dieses Prozesses nennt man ein Embedding – also die Einbettung von Bedeutung in einen mathematischen Raum. Jedes Embedding ist ein Vektor, und die Menge aller Embeddings bildet einen Vektorraumspeicher, den man durchsuchen kann.
3. Die Suche im Bedeutungsraum
Wie findet man nun etwas in diesem Raum? Statt Zeichenketten zu vergleichen (wie bei klassischen Suchmaschinen), misst man den Abstand zwischen Vektoren. Je kleiner dieser Abstand, desto ähnlicher sind sich die Bedeutungen.
Das am häufigsten verwendete Maß ist die Cosine Similarity. Sie berechnet den Winkel zwischen zwei Vektoren:
- Ein Winkel von 0° bedeutet, dass beide Vektoren in dieselbe Richtung zeigen → perfekte Bedeutungsähnlichkeit.
- Ein Winkel von 90° bedeutet völlige Unabhängigkeit.
Andere Methoden wie die Euclidean Distance (Luftlinie) oder die Dot Product Similarity (Skalarprodukt) kommen ebenfalls vor, aber die Cosine-Metrik ist der Standard, weil sie Richtung statt Größe bewertet.
Wenn also ein Nutzer „Texterstellung Online-Shop" sucht, wird die Anfrage in einen Vektor umgewandelt und mit allen gespeicherten Dokument-Vektoren verglichen. Das System liefert diejenigen zurück, die im semantischen Raum am nächsten liegen – selbst wenn sie ganz andere Wörter enthalten, wie etwa „Kategorietexte schreiben lassen".
4. Indexierung und Speicherstruktur
Damit das funktioniert, braucht es eine spezielle Form der Datenbank: einen Vektorindex. Er unterscheidet sich grundlegend von einem klassischen, auf Schlüsselwörtern basierenden Index.
Ein Keyword-Index ist im Prinzip eine Tabelle, die festhält, auf welcher Seite ein bestimmtes Wort vorkommt. Ein Vektorindex dagegen enthält numerische Repräsentationen, die nach Ähnlichkeit durchsucht werden.
Dafür werden oft sogenannte Approximate Nearest Neighbor (ANN)-Algorithmen verwendet. Diese Verfahren – wie HNSW (Hierarchical Navigable Small World) oder FAISS von Facebook – erlauben es, Milliarden von Vektoren schnell zu vergleichen, ohne alle Berechnungen vollständig durchführen zu müssen.
Das System speichert also nicht nur, wo ein Begriff vorkommt, sondern welche Bedeutung er hat. Dadurch kann es semantische Nähe erkennen, Kontext ableiten und sogar implizite Beziehungen finden – etwa zwischen „Sprachoptimierung" und „Tonalitätsanalyse", obwohl diese Wörter nichts gemeinsam haben.
5. Kontextuelle Ebene: Satz, Absatz, Dokument
In der Praxis arbeitet Vektorsuche auf mehreren Ebenen gleichzeitig:
Wortebene: für lexikalische Beziehungen (Synonyme, Antonyme).
Satzebene: für semantische Bedeutungseinheiten.
Absatz- und Dokumentebene: für thematische Zusammenhänge und Intention.
Ein gutes Beispiel liefert Google mit dem Passage-Ranking: Statt nur komplette Seiten zu bewerten, identifiziert das System relevante Textabschnitte, deren Vektoren besonders nahe an der Suchanfrage liegen. Das erklärt, warum ein einzelner Absatz in einem langen Artikel bei bestimmten Suchanfragen plötzlich ganz oben rankt.
6. Semantische Relevanz statt Wortidentität
Das Besondere an der Vektorsuche ist ihr Fokus auf semantische Relevanz statt auf Wortidentität. Früher galt: Ohne das richtige Keyword kein Ranking. Heute gilt: Wenn der inhaltliche Sinn übereinstimmt, kann auch ein anders formulierter Text erscheinen.
Suchmaschinen verstehen so, dass „Wie optimiere ich Texte für Suchmaschinen?" und „Wie verbessere ich die Auffindbarkeit von Inhalten?" dasselbe Anliegen ausdrücken. Das ermöglicht es, Inhalte natürlicher zu schreiben, weil das System nicht mehr an exakte Begriffe gebunden ist.
Für SEO bedeutet das eine Verschiebung: Entscheidend ist nicht, dass ein Keyword exakt vorkommt, sondern dass der Text ein kohärentes Bedeutungsnetz bildet. Eine Seite, die über semantische Suche, Kontextanalyse und KI-gestützte Texterstellung spricht, hat auch dann Relevanz für „semantische Indexierung", wenn dieses Wort nur einmal vorkommt.
7. Grenzen und Herausforderungen
So elegant das Prinzip ist, es hat auch Grenzen. Vektormodelle lernen aus vorhandenen Daten – und übernehmen deren Verzerrungen. Wenn ein Modell vor allem englischsprachige oder technische Texte kennt, kann es kulturelle, stilistische oder sprachliche Unterschiede falsch interpretieren.
Ein weiteres Problem ist die Erklärbarkeit. Warum zwei Vektoren als ähnlich gelten, lässt sich schwer nachvollziehen. Für SEO-Strategien bedeutet das, dass viele Ranking-Entscheidungen zunehmend undurchsichtig werden.
Hinzu kommt der hohe Rechenaufwand: Das Durchsuchen großer Vektorräume erfordert spezialisierte Hardware und komplexe Indexierungsverfahren. Deshalb arbeiten viele Systeme mit Hybrid Search, bei der Vektoren und Keywords gemeinsam genutzt werden – das Thema einer eigenen Unterseite.
8. Fazit: Bedeutung als Koordinate
Vektorsuche ist mehr als ein technisches Detail – sie ist der Schritt, der Suchmaschinen vom Zählen zum Verstehen geführt hat. Indem Sprache in Vektorräume übersetzt wird, können Maschinen semantische Beziehungen erkennen, Konzepte verknüpfen und Informationen kontextbezogen bereitstellen.
Für SEO, Content-Architektur und Textoptimierung bedeutet das:
- Inhalte müssen Bedeutung tragen, nicht nur Wörter.
- Themenfelder sollten semantisch vernetzt sein, statt isoliert.
- Der Fokus liegt auf Kontextqualität statt Keyword-Dichte.
Die Vektorsuche ist damit das Fundament der semantischen Indexierung – und der Schlüssel zum Verständnis, warum moderne Suchmaschinen immer seltener nach Wörtern suchen, sondern nach Sinn.
Über den Autor
Marcus A. Volz ist Linguist und Spezialist für semantische KI-Systeme bei eLengua. Er analysiert, wie Suchmaschinen Bedeutung verstehen – von Vektorräumen über Embeddings bis zur semantischen Indexierung. Seine Arbeit verbindet theoretische Sprachwissenschaft mit praktischer Anwendung in SEO und Content-Optimierung.
Häufig gestellte Fragen (FAQ)
Was ist ein Vektor in der Vektorsuche?
Ein Vektor ist eine Reihe von Zahlen – etwa [0.12, 0.48, -0.37, …]. Jede Zahl repräsentiert eine Dimension, und gemeinsam bilden sie einen Punkt im Raum. Wenn man jedes Wort auf diese Weise abbildet, entsteht ein mehrdimensionaler Bedeutungsraum, in dem semantisch ähnliche Wörter eng beieinanderliegen.
Wie werden Texte in Vektoren umgewandelt?
Die Umwandlung geschieht durch Trainingsmodelle wie Word2Vec, BERT oder Sentence-BERT, die auf großen Textkorpora basieren. Diese Modelle lernen, welche Wörter häufig gemeinsam auftreten und wie sie sich gegenseitig beeinflussen. Das Ergebnis nennt man ein Embedding – die Einbettung von Bedeutung in einen mathematischen Raum.
Was ist Cosine Similarity?
Cosine Similarity berechnet den Winkel zwischen zwei Vektoren. Ein Winkel von 0° bedeutet perfekte Bedeutungsähnlichkeit (beide Vektoren zeigen in dieselbe Richtung), ein Winkel von 90° bedeutet völlige Unabhängigkeit. Sie ist das am häufigsten verwendete Maß, weil sie Richtung statt Größe bewertet.
Was unterscheidet einen Vektorindex von einem Keyword-Index?
Ein Keyword-Index ist eine Tabelle, die festhält, auf welcher Seite ein bestimmtes Wort vorkommt. Ein Vektorindex enthält numerische Repräsentationen, die nach Ähnlichkeit durchsucht werden. Er speichert nicht nur, wo ein Begriff vorkommt, sondern welche Bedeutung er hat.
Was sind ANN-Algorithmen?
Approximate Nearest Neighbor (ANN)-Algorithmen wie HNSW oder FAISS erlauben es, Milliarden von Vektoren schnell zu vergleichen, ohne alle Berechnungen vollständig durchführen zu müssen. Sie machen die Vektorsuche in großen Datenmengen praktisch umsetzbar.
Was ist der Unterschied zwischen Wortidentität und semantischer Relevanz?
Früher galt: Ohne das richtige Keyword kein Ranking (Wortidentität). Heute gilt: Wenn der inhaltliche Sinn übereinstimmt, kann auch ein anders formulierter Text erscheinen (semantische Relevanz). Suchmaschinen verstehen, dass „Wie optimiere ich Texte für Suchmaschinen?" und „Wie verbessere ich die Auffindbarkeit von Inhalten?" dasselbe Anliegen ausdrücken.
Was ist Passage-Ranking?
Passage-Ranking ist eine Google-Technik, bei der nicht nur komplette Seiten bewertet werden, sondern relevante Textabschnitte identifiziert werden, deren Vektoren besonders nahe an der Suchanfrage liegen. Deshalb kann ein einzelner Absatz in einem langen Artikel bei bestimmten Suchanfragen ganz oben ranken.
Was ist Hybrid Search?
Hybrid Search kombiniert Vektorsuche mit klassischer Keyword-Suche. Da das Durchsuchen großer Vektorräume hohen Rechenaufwand erfordert, arbeiten viele Systeme mit dieser Kombination, um die Vorteile beider Methoden zu nutzen – semantisches Verständnis und präzise Begriffstreffer.